AIエージェントが盛り上がっていますが、丸投げせず無料で効率的に使う方法を思いつき、実践してみました。ちなみに有料AIは使ったことがありません。Cursorの良いところは、フォルダ内の複数ファイルの関係性を把握でき、制限にすぐ達しても無料で高性能モデルが使える点です。
結論は、
・フォルダ内容を絞り、本質的に関係ない部分は削除する。
・不要な質問はしない。
この2点でトークン数を節約します。無料枠のためでもありますが、この方が精度の高い回答が得られると考えています。どんどん扱えるコンテキストサイズが大きくなってるモデルが登場していますが、情報過多(LLMに入れるファイル数や、プロンプト、回答)は良くないと感じます。
そのため事前準備と適切なプロンプト作成が重要です。
実際にやったことは対象プロジェクト(今回はDjango)をローカルに取り込み、不要なアプリなどを削除(今回、ファイルサイズ177Mから14.8Mに縮小)。原因の見当をつけてプロンプトを準備し、デバッグはCursorでは行わず、ローカルや本番環境で実施。行き詰まったらGemini、ChatGPT、Copilot、Claudeなど無料ツールに相談。ここぞというところでCursorに再度質問という感じで、2回のプロンプトだけで解決しました。
今回は本番環境で発生したサーバーエラーの原因を調査しました。
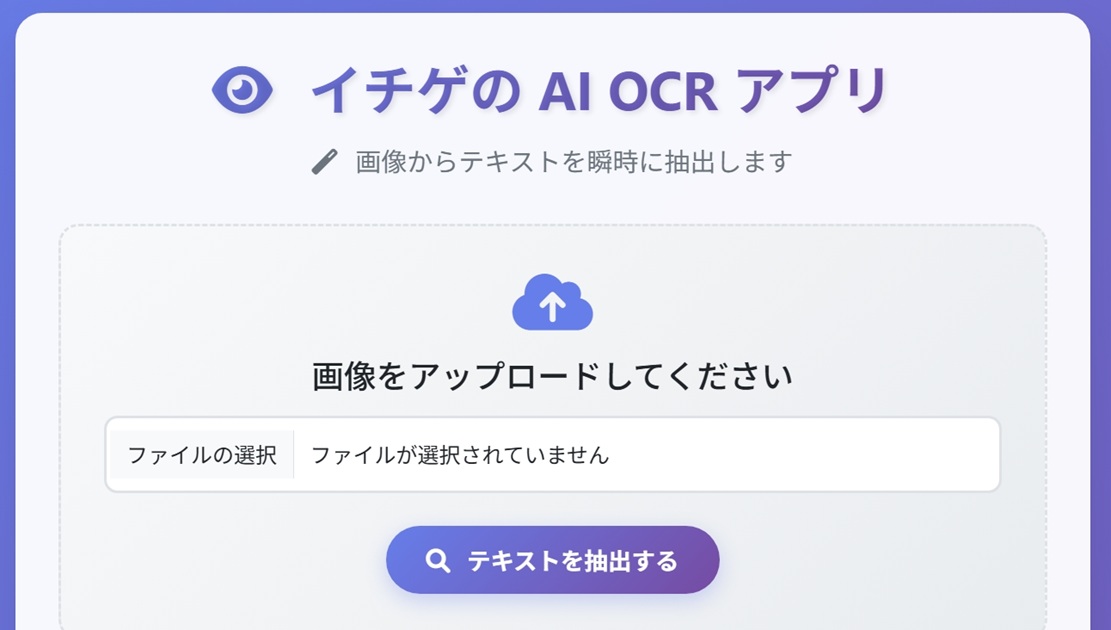
対象アプリはイチゲのAI OCRアプリです。
アプリの詳細は
GeminiCLIはCursor同様、フォルダ内を無料で解析でき、高性能モデルの制限に達しても自動で低性能モデルに切り替えて継続利用可能。フォルダ内の複数ファイルを扱う際に便利です。
準備
2026/5/6、1年ぶりにCursorを使ってみた。ずいぶん使い方が変わっている。
・fileからopenfolderで対象のDjangoのプロジェクトのフォルダを開く。
・view→filesでフォルダが見れて、ファイルを選択すると中身も見れる。
・view→settings→modelesでONになってるモデルを確認した。
Composer 2、Codex 5.3、Sonnet 4.6、GPT-5.5、Opus 4.7
Cursorへのプロンプトと回答
プロンプト
「本番環境でアプリ’uploader’を実行してるとき、うまくいくときもあるが、たまにServer エラーになる。具体的な操作として「テキストを抽出する」を押した後でエラーになる。エラーコードなどは出ない。サーバーのメモリは1Gしかなく、他にWordPressやDjangoのアプリなど複数起動している。GeminiのAPIは無料枠を使っていて、制限に引っかかっている場合は、Serverエラーではなく、結果画面にエラーコードが表示される。」
Cursorの回答
状況の整理
uploader の「テキストを抽出する」は、フォーム POST で upload_file が動き、一時ファイルに保存 → ocr_image(Gemini)→ セッションに OCR 結果と画像の data URI(base64 全文)を保存 → display_result へリダイレクト、という流れです。
# 一時ファイルにチャンクで書き出し(メモリ消費最小化)
with tempfile.NamedTemporaryFile(delete=True, suffix=f”.{image_file.name.split(‘.’)[-1]}”) as temp_img_file:
for chunk in image_file.chunks():
temp_img_file.write(chunk)
temp_img_file.flush()
temp_img_file.seek(0)
# OCR処理
ocr_result = ocr_image(temp_img_file)
# base64エンコード用に一時的に全データを読み込む
temp_img_file.seek(0)
image_data = temp_img_file.read()
base64_image = base64.b64encode(image_data).decode(‘utf-8’)
data_uri = f”data:{image_file.content_type};base64,{base64_image}”
request.session[‘ocr_result’] = ocr_result
request.session[‘uploaded_file_data_uri’] = data_uri
return redirect(‘display_result’)
一方、Gemini まわりは 例外を握りつぶして文字列で返している ので、API エラーはだいたい結果画面の <pre> にそのまま出ます。
try:
response = model.generate_content([prompt, img], stream=True)
response.resolve()
return response.text
except Exception as e:
return f”Error calling Gemini API: {e}”
そのため、「無料枠の制限=結果画面にエラー文」という体感とコードは整合しやすいです。
「Server エラー」でコードが出ない理由
ブラウザに詳細が出ないのは typical に次のどれかです。
- プロセスがリクエスト処理の途中で落ちた(Linux の OOM Killer で SIGKILL など)
- Django の
try/exceptに届かないので、結果画面にも行けない。 - 1GB で WordPress・別 Django・DB などと同居していると、画像+Pillow+Gemini クライアント+base64 用のバイト列が重なった瞬間だけメモリが足りなくなる、というパターンがあり得ます。
- Django の
- リバースプロキシ/WSGI サーバのタイムアウト
- Gemini の応答が遅い回だけ worker や upstream が切られる → 502/504 や「サーバーエラー」表示で、本文に Django のメッセージは載らない。
- セッション保存まわりの例外(SQLite 利用時など)
- 設定では DB が SQLite です。セッションに 数 MB 級の data URI を毎回書き込むと、I/O・ロック・負荷が重くなり、状況によっては
database is lockedなどで 500 になり得ます(同時アクセスや他アプリとディスク競合があると「たまに」になりやすい)。
- 設定では DB が SQLite です。セッションに 数 MB 級の data URI を毎回書き込むと、I/O・ロック・負荷が重くなり、状況によっては
- 本番だけ
DEBUG = Falseの場合- 未処理の例外は 汎用 500 ページ になり、ユーザーにはコードやスタックが見えません(リポジトリ上は
DEBUG = Trueですが、VPS 上の実設定が違う可能性はあります)。
- 未処理の例外は 汎用 500 ページ になり、ユーザーにはコードやスタックが見えません(リポジトリ上は
切り分けの手順(サーバー上で確認)
優先度の高い順です。
| 確認 | 意味 |
|---|---|
dmesg や journalctl -k で Out of memory / Killed process | OOM の有無 |
| Nginx/Apache の error.log の upstream timed out / 502 | タイムアウト |
Django/Gunicorn のログに database is locked や MemoryError | SQLite・メモリ |
| エラー時の HTTP ステータス(502/504 vs 500) | プロキシ問題かアプリ問題かの目安 |
対策の方向性(根本的には負荷とセッション設計)
- メモリ: VPS の RAM 増設、または OCR 用ワーカー/コンテナを分離。
- タイムアウト:
proxy_read_timeout(Nginx)や Gunicorn のtimeoutを、Gemini の遅延に合わせて延長(上限は運用で調整)。 - セッション: 結果画面用画像を セッションに巨大 data URI で載せない(短い ID +キャッシュ/一時ファイル/別ストレージに退避)と、メモリ・SQLite・クッキーサイズの問題をまとめて弱められます。
結論: コード上、Gemini の制限は結果画面に文字で出やすく、「たまに」「Server エラー」「詳細なし」 は メモリ不足(OOM)・プロキシ/worker タイムアウト・SQLite+肥大セッション が特に疑わしいです。まずサーバーログと dmesg で OOM/タイムアウトを確認するのが近道です。
必要なら、セッションに載せない実装案までこのリポジトリに合わせて具体的に書けます。
かなり的を得た回答に思える。
切り分けの手順(サーバー上で確認)のアドバイスをもらった。ここで列挙されてるコマンドは、そのまま使えないことが多いので、あとは、Cursorで聞かず、サーバー使って、他の低級無料AIモデルに聞いて頑張る。その時点で解決する場合もあるが、解決しない場合、やってるうちにある程度、ポイントが絞れてくるので、そこでCursorで高級モデルに聞く。
サーバーで調査
確認項目に「Django/Gunicorn のログに database is locked や MemoryError」があったので以下コマンドで見た。コマンドはCursorに聞かずGeminiに聞いた。
sudo docker logs django_コンテナ名 -f
原因となりそうな部分数行だけをchousa\djangoerr.txtにコピペしてCursorで聞いた。
抜粋
[2026-05-05 04:35:35 +0000] [1] [CRITICAL] WORKER TIMEOUT (pid:51)
[2026-05-05 13:35:35 +0900] [51] [ERROR] Error handling request POST /drakuten/uploader/
略
172.21.0.8 - - [05/May/2026:13:35:36 +0900] "POST /drakuten/uploader/ HTTP/1.0" 500 0 "-" "-"
[2026-05-05 13:35:36 +0900] [51] [INFO] Worker exiting (pid: 51)
[2026-05-05 04:35:36 +0000] [1] [ERROR] Worker (pid:51) was sent SIGKILL! Perhaps out of memory?
[2026-05-05 04:35:37 +0000] [72] [INFO] Booting worker with pid: 72再度Cursorに聞いた
プロンプト「sudo docker logs django_コンテナ名 -fで表示したログを@chousaのdjangoerr.txtにエラー発生時のログを記録しました。」←日本語がおかしいが通じた。
Cursorの回答
ログから原因はほぼ確定で、Gunicorn の WORKER TIMEOUT → SIGKILL (Perhaps out of memory?) が出ています。次に、(a) Gunicorn のタイムアウト設定と (b) OCR処理を軽くする(特に stream=True とセッション巨大保存)両面で再発率を下げる修正を入れます。まず Gunicorn の起動設定がどこにあるか探します。
いまのログは「Gemini 呼び出しが返ってくる前に Gunicorn がタイムアウト → worker を落とす(最終的に SIGKILL / OOM疑い)」という流れです。再発を抑えるために、まず (1) stream=True をやめて待ち時間を短くし、(2) セッションに巨大な base64 を保存せず POST 直後に結果を描画するように直します。続いて (3) docker の gunicorn に --timeout を付ける修正を入れます。
import io
from dotenv import load_dotenv
from django.conf import settings
def ocr_image(image_file_object) -> str:
load_dotenv()
# api_key = os.getenv(“GEMINI_API_KEY”)
api_key= settings.GEMINI_API_KEY
try:
response = model.generate_content([prompt, img], stream=True)
response.resolve()
return response.text
# stream=True は「最初の応答まで」に時間がかかると Gunicorn timeout に当たりやすいので避ける
response = model.generate_content([prompt, img])
return getattr(response, “text”, str(response))
except Exception as e:
ログ結論(原因)
chousa/djangoerr.txt の L4〜L115 から、エラーの正体は Gemini 呼び出し中に Gunicorn が WORKER TIMEOUT を起こし、worker が終了 → SIGKILL! Perhaps out of memory? まで行っているケースです。つまり「Gemini無料枠の制限」ではなく、本番の処理時間+1GB環境の余裕不足が主因です。
いま入れた対策(コード反映済み)
stream=Trueをやめる(最初のレスポンスが返る前に待たされやすく、Gunicorn timeout と相性が悪い)- セッションに巨大な
data:base64 を保存しない(SQLite セッションDB/メモリの負荷を上げやすい)
→ POST の応答でそのままresult.htmlを返す方式に変更
変更箇所は uploader/views.py です。
def ocr_image(image_file_object) -> str:
api_key= settings.GEMINI_API_KEY
if not api_key:
return “Error: GEMINI_API_KEY not found in .env file or environment variables.”
genai.configure(api_key=api_key)
model = genai.GenerativeModel(‘gemini-3-flash-preview’) #2026/4/9 model変更
try:
img = PIL.Image.open(image_file_object)
except Exception as e:
return f”Error opening image: {e}”
prompt = “Extract all text from this image, including any handwritten text. Preserve the original line breaks and formatting as much as possible.”
try:
# stream=True は「最初の応答まで」に時間がかかると Gunicorn timeout に当たりやすいので避ける
response = model.generate_content([prompt, img])
return getattr(response, “text”, str(response))
except Exception as e:
return f”Error calling Gemini API: {e}”
# …
# セッションに巨大な data URI を保存するとDB/メモリ負荷が上がりやすいので、POSTの応答で結果を返す
return render(request, ‘uploader/result.html’, {
‘ocr_result’: ocr_result,
‘uploaded_file_data_uri’: data_uri
})
いま入れた対策(デプロイ設定)
Docker の Gunicorn 起動コマンドに タイムアウト延長を追加しました(まずは 120 秒)。
onamaevps2/docker-compose.yml の command を変更済みです。
次の作業(VPS側でやること)
docker compose up -d --build(または同等の手順)でコンテナを再起動- 以後、同じ操作で Server エラーが出るか確認
- まだ出る場合は、ログにまた
WORKER TIMEOUTが出ているか、SIGKILLが出ているかで追加対策(timeout さらに延長/ワーカー種類変更/メモリ増設/画像表示の軽量化)に進めます
必要なら、display_result(/result/)も「セッション無しで開かれた時は upload に戻す」挙動に変えて、誤アクセスを避けるように整えます。
コードを変更してくれたので保存。本番環境に採用して動作確認した。うまくいってそう。様子見中。
使用したトークン数
左下の歯車マーク(Viewのsettings)→ Cursor AccountのopenでCursorのDashboardが開きます。
Usageで確認できます。metricがspendとtokensで切り替えられるのでtokensにします。
使用したトークン数は430.9kトークンでした。ちなみに、その時点でspendは0.17ドル
https://cursor.com/ja/pricingここを見ても制限に関しては、よくわからんし、spendが気になる。
こういうのはGrokに聞くのがいいので聞いた。
プロンプト
「hobbyプランで使っているが、usageをみると以下のようになっている。請求されるのか
Total spend$1.14
Included$1.14
On-demand$0」
Grokの回答
いいえ、請求はされません。
cursor.comHobbyプラン(無料プラン)はクレジットカード登録不要で、完全に無料です。
表示されている「Total spend $1.14 / Included $1.14 / On-demand $0」の意味は以下の通りです:
- Total spend $1.14: 今月使った使用量をドル換算した金額(目安)。
- Included $1.14: その全額が**無料枠(Included)**から消費された。
- On-demand $0: 追加課金(有料の従量課金)は一切発生していない。
なぜ請求されないか
- Hobbyプランは最初から限定された無料使用量のみ提供され、**On-demand(追加課金)**を有効にしない限り(または有効にできなかったり)超えても自動で課金されません。
- 無料枠を使い切ると、通常は低速モデルに制限されたり、Agentリクエストが一時的に使えなくなったりしますが、お金はかかりません。
注意点
- 使い続けたい場合は**Proプラン($20/月)**へのアップグレードを検討してください。Proなら$20分の使用量が含まれ、Tab補完無制限などになります。
- 使用量はcursor.com/dashboard(または設定内のUsage)でいつでも確認できます。制限に近づくとエディタ内で通知が出るはずです。
Hobbyで軽く使っている分には完全に無料なので安心してください!
もっと詳しく知りたい場合(例: 現在の残り使用量など)は、ダッシュボードのスクリーンショットを教えてくれればさらに解説できます。
所感
2回のプロンプトで解決することができた。どのくらいトークンを消費したかわからないが制限には引っかかっていない。有料のAIを使ったことがないが、無料枠でも使い方を工夫すれば十分、事足りる。もしかして、有料のAIエージェントに丸投げして大量のトークン消費するより解決するかも。
この記事を書いたイチゲを応援する(質問でもokです)
Vプリカでのお支払いがおすすめです。